 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoMotion: Hierarchical Reasoning and Diffusion for Egocentric Vision-Language Motion Generation
Apr 21, 2026Faithfully modeling human behavior in dynamic environments is a foundational challenge for embodied intelligence. While conditional motion synthesis has achieved significant advances, egocentric motion generation remains largely underexplored due to the inherent complexity of first-person perception. In this work, we investigate Egocentric Vision-Language (Ego-VL) motion generation. This task requires synthesizing 3D human motion conditioned jointly on first-person visual observations and natural language instructions. We identify a critical \textit{reasoning-generation entanglement} challenge: the simultaneous optimization of semantic reasoning and kinematic modeling introduces gradient conflicts. These conflicts systematically degrade the fidelity of multimodal grounding and motion quality. To address this challenge, we propose a hierarchical generative framework \textbf{EgoMotion}. Inspired by the biological decoupling of cognitive reasoning and motor control, EgoMotion operates in two stages. In the Cognitive Reasoning stage, A vision-language model (VLM) projects multimodal inputs into a structured space of discrete motion primitives. This forces the VLM to acquire goal-consistent representations, effectively bridging the semantic gap between high-level perceptual understanding and low-level action execution. In the Motion Generation stage, these learned representations serve as expressive conditioning signals for a diffusion-based motion generator. By performing iterative denoising within a continuous latent space, the generator synthesizes physically plausible and temporally coherent trajectories. Extensive evaluations demonstrate that EgoMotion achieves state-of-the-art performance, and produces motion sequences that are both semantically grounded and kinematically superior to existing approaches.
DreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Jan 29, 2026Character image animation aims to synthesize high-fidelity videos by transferring motion from a driving sequence to a static reference image. Despite recent advancements, existing methods suffer from two fundamental challenges: (1) suboptimal motion injection strategies that lead to a trade-off between identity preservation and motion consistency, manifesting as a "see-saw", and (2) an over-reliance on explicit pose priors (e.g., skeletons), which inadequately capture intricate dynamics and hinder generalization to arbitrary, non-humanoid characters. To address these challenges, we present DreamActor-M2, a universal animation framework that reimagines motion conditioning as an in-context learning problem. Our approach follows a two-stage paradigm. First, we bridge the input modality gap by fusing reference appearance and motion cues into a unified latent space, enabling the model to jointly reason about spatial identity and temporal dynamics by leveraging the generative prior of foundational models. Second, we introduce a self-bootstrapped data synthesis pipeline that curates pseudo cross-identity training pairs, facilitating a seamless transition from pose-dependent control to direct, end-to-end RGB-driven animation. This strategy significantly enhances generalization across diverse characters and motion scenarios. To facilitate comprehensive evaluation, we further introduce AW Bench, a versatile benchmark encompassing a wide spectrum of characters types and motion scenarios. Extensive experiments demonstrate that DreamActor-M2 achieves state-of-the-art performance, delivering superior visual fidelity and robust cross-domain generalization. Project Page: https://grisoon.github.io/DreamActor-M2/
CLIP-Guided Adaptable Self-Supervised Learning for Human-Centric Visual Tasks
Jan 19, 2026Human-centric visual analysis plays a pivotal role in diverse applications, including surveillance, healthcare, and human-computer interaction. With the emergence of large-scale unlabeled human image datasets, there is an increasing need for a general unsupervised pre-training model capable of supporting diverse human-centric downstream tasks. To achieve this goal, we propose CLASP (CLIP-guided Adaptable Self-suPervised learning), a novel framework designed for unsupervised pre-training in human-centric visual tasks. CLASP leverages the powerful vision-language model CLIP to generate both low-level (e.g., body parts) and high-level (e.g., attributes) semantic pseudo-labels. These multi-level semantic cues are then integrated into the learned visual representations, enriching their expressiveness and generalizability. Recognizing that different downstream tasks demand varying levels of semantic granularity, CLASP incorporates a Prompt-Controlled Mixture-of-Experts (MoE) module. MoE dynamically adapts feature extraction based on task-specific prompts, mitigating potential feature conflicts and enhancing transferability. Furthermore, CLASP employs a multi-task pre-training strategy, where part- and attribute-level pseudo-labels derived from CLIP guide the representation learning process. Extensive experiments across multiple benchmarks demonstrate that CLASP consistently outperforms existing unsupervised pre-training methods, advancing the field of human-centric visual analysis.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
Morph: A Motion-free Physics Optimization Framework for Human Motion Generation
Nov 22, 2024Human motion generation plays a vital role in applications such as digital humans and humanoid robot control. However, most existing approaches disregard physics constraints, leading to the frequent production of physically implausible motions with pronounced artifacts such as floating and foot sliding. In this paper, we propose \textbf{Morph}, a \textbf{Mo}tion-f\textbf{r}ee \textbf{ph}ysics optimization framework, comprising a Motion Generator and a Motion Physics Refinement module, for enhancing physical plausibility without relying on costly real-world motion data. Specifically, the Motion Generator is responsible for providing large-scale synthetic motion data, while the Motion Physics Refinement Module utilizes these synthetic data to train a motion imitator within a physics simulator, enforcing physical constraints to project the noisy motions into a physically-plausible space. These physically refined motions, in turn, are used to fine-tune the Motion Generator, further enhancing its capability. Experiments on both text-to-motion and music-to-dance generation tasks demonstrate that our framework achieves state-of-the-art motion generation quality while improving physical plausibility drastically.
M$^3$GPT: An Advanced Multimodal, Multitask Framework for Motion Comprehension and Generation
May 29, 2024This paper presents M$^3$GPT, an advanced $\textbf{M}$ultimodal, $\textbf{M}$ultitask framework for $\textbf{M}$otion comprehension and generation. M$^3$GPT operates on three fundamental principles. The first focuses on creating a unified representation space for various motion-relevant modalities. We employ discrete vector quantization for multimodal control and generation signals, such as text, music and motion/dance, enabling seamless integration into a large language model (LLM) with a single vocabulary. The second involves modeling model generation directly in the raw motion space. This strategy circumvents the information loss associated with discrete tokenizer, resulting in more detailed and comprehensive model generation. Third, M$^3$GPT learns to model the connections and synergies among various motion-relevant tasks. Text, the most familiar and well-understood modality for LLMs, is utilized as a bridge to establish connections between different motion tasks, facilitating mutual reinforcement. To our knowledge, M$^3$GPT is the first model capable of comprehending and generating motions based on multiple signals. Extensive experiments highlight M$^3$GPT's superior performance across various motion-relevant tasks and its powerful zero-shot generalization capabilities for extremely challenging tasks.
Fast and parallel decoding for transducer
Oct 31, 2022The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022



Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Pruned RNN-T for fast, memory-efficient ASR training
Jun 23, 2022

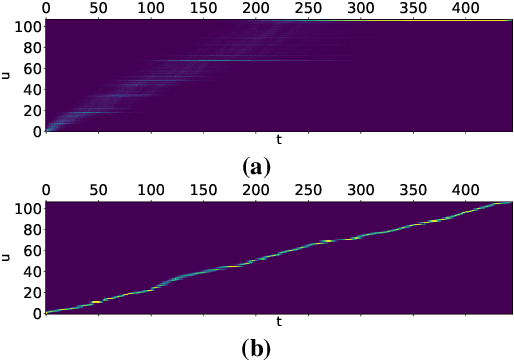
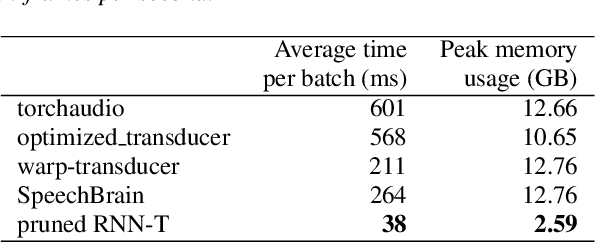
The RNN-Transducer (RNN-T) framework for speech recognition has been growing in popularity, particularly for deployed real-time ASR systems, because it combines high accuracy with naturally streaming recognition. One of the drawbacks of RNN-T is that its loss function is relatively slow to compute, and can use a lot of memory. Excessive GPU memory usage can make it impractical to use RNN-T loss in cases where the vocabulary size is large: for example, for Chinese character-based ASR. We introduce a method for faster and more memory-efficient RNN-T loss computation. We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is linear in the encoder and decoder embeddings; we can evaluate this without using much memory. We then use those pruning bounds to evaluate the full, non-linear joiner network.
Synchronous Bidirectional Learning for Multilingual Lip Reading
May 12, 2020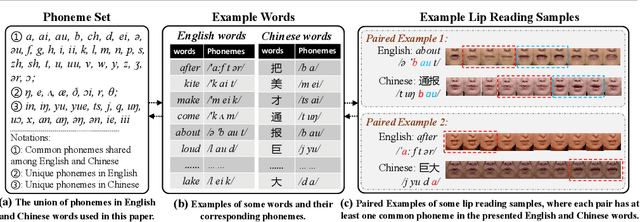
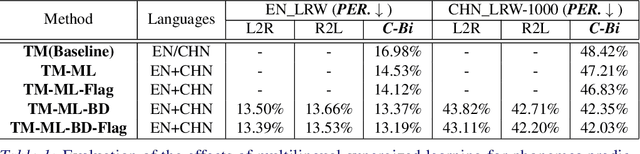
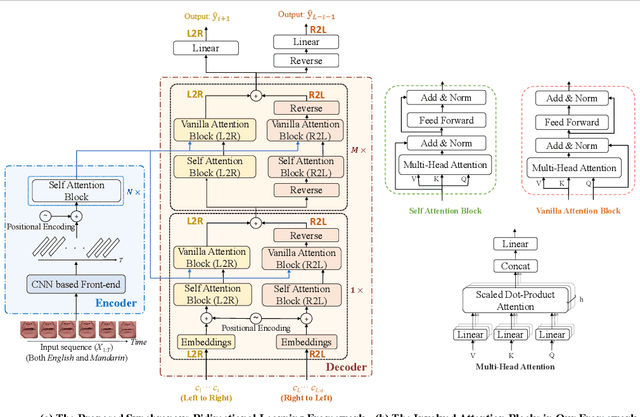
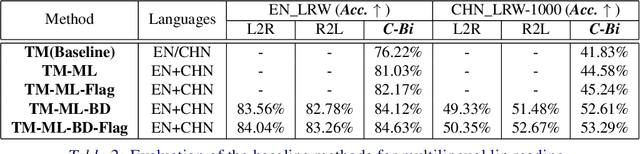
Lip reading has received increasing attention in recent years. This paper focuses on the synergy of multilingual lip reading. There are more than 7,000 languages in the world, which implies that it is impractical to train separate lip reading models by collecting large-scale data per language. Although each language has its own linguistic and pronunciation features, the lip movements of all languages share similar patterns. Based on this idea, in this paper, we try to explore the synergized learning of multilingual lip reading, and further propose a synchronous bidirectional learning(SBL) framework for effective synergy of multilingual lip reading. Firstly, we introduce the phonemes as our modeling units for the multilingual setting. Similar phoneme always leads to similar visual patterns. The multilingual setting would increase both the quantity and the diversity of each phoneme shared among different languages. So the learning for the multilingual target should bring improvement to the prediction of phonemes. Then, a SBL block is proposed to infer the target unit when given its previous and later context. The rules for each specific language which the model itself judges to be is learned in this fill-in-the-blank manner. To make the learning process more targeted at each particular language, we introduce an extra task of predicting the language identity in the learning process. Finally, we perform a thorough comparison on LRW (English) and LRW-1000(Mandarin). The results outperform the existing state of the art by a large margin, and show the promising benefits from the synergized learning of different languages.